Manuscript Speculation Tool: Reconstructing Non-extant Portions of Manuscripts
Part I: General Introduction
by
Diliana Atanassova, Troy A. Griffitts, and Ulrich Schmid
The codicological reconstruction of the manuscripts from the Library of the White Monastery in Upper Egypt is one of the biggest challenges in Coptology. In order to achieve its final score – the reconstruction of the Coptic Translation of the Old Testament – the Göttingen CoptOT Team has first to identify new biblical fragments from the White Monastery in the different museums and libraries all over the world, and second to find their original codex among already known codices. Once we know the leaves which belong to a codex, our next task is to put them together in a correct succession and if possible to find out exactly how many leaves are missing. The codicological reconstruction depends on how many leaves survive, how much of each leaf is preserved, and if the leaf still bears its original pagination and quire numbers. However, many of the leaves we have today are fragmentary and often lacking their upper margins. In order to facilitate the reconstruction of the pagination and quire numbers in such cases and also determine the amount of missing leaves in between two extant leaves, the authors of this blogpost have developed the Manuscript Speculation Tool by applying algorithms to this set of problems.
The parameters of the Manuscript Speculation Tool
This tool “reconstructs” missing pages based on a running text of one or more biblical books. In order for it to succeed it has to have a Basetext and certain parameters filled in that are derived from existing pages.
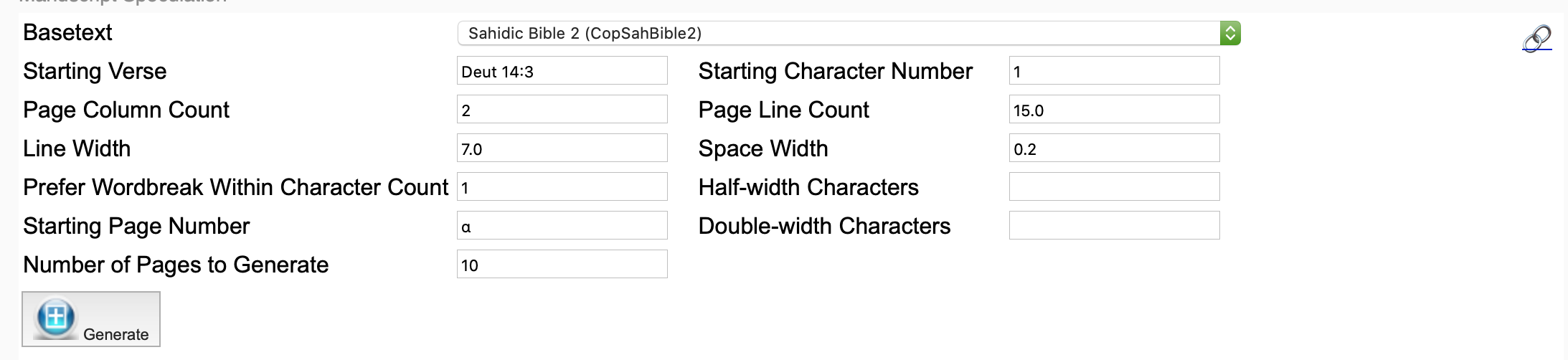
The first parameter, Basetext will be set to Sahidic Bible 2 for our work on the White Monastery leaves.
Starting Verse – here we enter the Biblical verse at which the tool should start a guess.
Starting Character Number – the character offset within the Starting Verse at which the tool should start to count. If nothing is entered the tool will start the count at the first letter of the first verse.
Page Column Count – the number of columns per page.
Page Line Count – the number of lines per page; you can use a decimal value to account for a range between two numbers.
Line Width – the number of letters per line; you can supply an average decimal value to account for variation of line width within the manuscript.
Space Width – the fraction of a character width to use between words. 0 for no space between words; 0.5 for half a character width between words, etc.
Prefer Wordbreak Within Character Count – lines can end exactly on the specified Line Width count or can be adjusted slightly if you find that the scribe preferred to end lines on a word break if the word break was within a reasonable amount of characters, e.g. "1" here would allow the line width to adjust by one character more or one character less if it would result in the line ending on a word break. If your strategy is to match the end of an extant page by adjusting fractional line length values, turning this feature off (setting to 0) is ideal.
Half-width Characters – some characters such as iota are often written using less than a full character width both in unimodular and bimodular manuscripts. Supply a list of characters here which should be treated as such.
Double-width Characters – to better support bimodular manuscript, a list of characters can be provided here which should be treated as double the normal character width when they occur on a line.
Starting Page Number – the number of the page at which the speculation should start.
Number of Pages to Generate – the number of successive pages that the tool should generate.
When you refine your parameters to best match your manuscript, you can then save or share those parameters with colleagues by using the “Return Link” icon in the upper right corner of the tool.
From a methodological point of view we are attempting to establish the tendencies of the Coptic scribe as discovered through the extant portions of the manuscript and apply those same tendencies when reconstructing the missing portions. This method was already used in traditional Coptological investigation, however this work was previously done manually and being very tedious, generally only for a few leaves.[1] Now, through the support of DH software we can reach a new level of speed and consistency in applying our expert decisions, thus increasing accuracy and assuring plausibility for our assumptions. This tool is now integrated and available within the Virtual Manuscript Room and can be used not only for the Coptic biblical codices from the White Monastery but also for all Coptic or other language biblical manuscripts. You can find the Manuscript Speculation Tool here.
Finally, we would like to end the first part of our blogpost with five concise suggestions based on what we have learned by using the tool over the past months.
- Know your codex thoroughly.
- Try to reconstruct an extant page in order to prove your speculative parameter values.
- Use the tool only to close the gap between two leaves, so as not to carry errors onward to the next gap.
- Attempt to find other possibilities for best speculation values by tuning different parameters.
- Tolerate errors. The tool can only speculate and will never be exact.
In the second part of this blog post we will be using the tool to reconstruct the non-extant portion of the fragmentary manuscript sa 2070. You are invided to follow us there.
---------------------------------------------
[1] D. Atanassova, “Neue Erkenntnisse bei der Erforschung der sahidischen Quellen für die Paschawoche”, in: Heike Behlmer, Ute Pietruschka, Frank Feder (eds.), Ägypten und der Christliche Orient. Peter Nagel zum 80. Geburtstag (Texte und Studien zur Koptischen Bibel 1), Wiesbaden 2018, pp. 1–37, particularly p. 20.
 Blogs
Blogs 